
The Architecture Behind Rezzy's Resume Tailoring AI Agent
How we built a production-grade resume tailoring system using two specialized models orchestrated through LangGraph, instead of forcing one model to do everything.
Rezzy started with a simple idea: build the most reliable, accurate, production-grade resume tailoring tool out there. But very quickly, we realized something important: resume tailoring looks simple from the outside, but it’s actually very nuanced.
Strategy and execution are completely different skill sets, and any model trying to do both at the same time will eventually trip on one of them.
That’s the entire reason Rezzy’s AI works the way it does today. It’s not “one big model with a fancy prompt.” It’s two different models, each doing what they’re best at, orchestrated through LangGraph so they behave like a single intelligent agent.
And honestly, this architecture only happened because we kept breaking things while trying to force a single-model solution.
Why Resume Tailoring Is More Complex Than It Looks
If you've ever tailored your own resume, you know exactly why an LLM struggles.
It's not just: "Match resume → job → rewrite."
It's: Should this side project stay? Should that retail job from 2019 even be mentioned? Is this skill relevant or just another buzzword? Which bullets deserve expansion? Which bullets are fluff? How do you fit all of this on one page without losing substance?
These are strategic decisions. They're not formatting. They're not rewriting. They're closer to editorial judgement - the kind humans argue about on Reddit all day.

When we first tried to solve this with a single LLM (we even gave GPT 5.1 a massive system prompt), the results were exactly what you'd expect:
- It would make strong strategic decisions but hallucinate details during execution.
- Or, it would execute precisely but completely miss the bigger picture.
- Sometimes it would just overload the context window and fall apart entirely.
That's when we realized: strategy and execution must be separated.
The Core Idea Behind Rezzy's Architecture
So here's the design decision that changed everything: Let Claude handle strategy. Let OpenAI handle execution.
This ended up solving almost every reliability issue we hit early on.
Claude 4.5 Sonnet is used for deep reasoning, structured thinking, nuanced judgement, which allows it to follow our 200 lines of instructions without getting lost. It behaves like a recruiter who reads the resume, reads the job description, sits back for a second, and says, "Okay, here's the plan."
OpenAI GPT 5.1 is the opposite. It's used for following rules, generating structured output, following the STAR (Situation, Task, Action, Result) framework to write description points, staying grounded, and making small, careful edits. Exactly what you want from an "execution engine."

So instead of forcing one model to do both jobs, we designed a pipeline where:
- Claude produces a strategic "blueprint"
- OpenAI transforms that blueprint into an actual resume
- Both models stay in their lanes
- And LangGraph stitches the whole thing together
The result is a system that feels intentional instead of chaotic.
How the Agent Actually Works
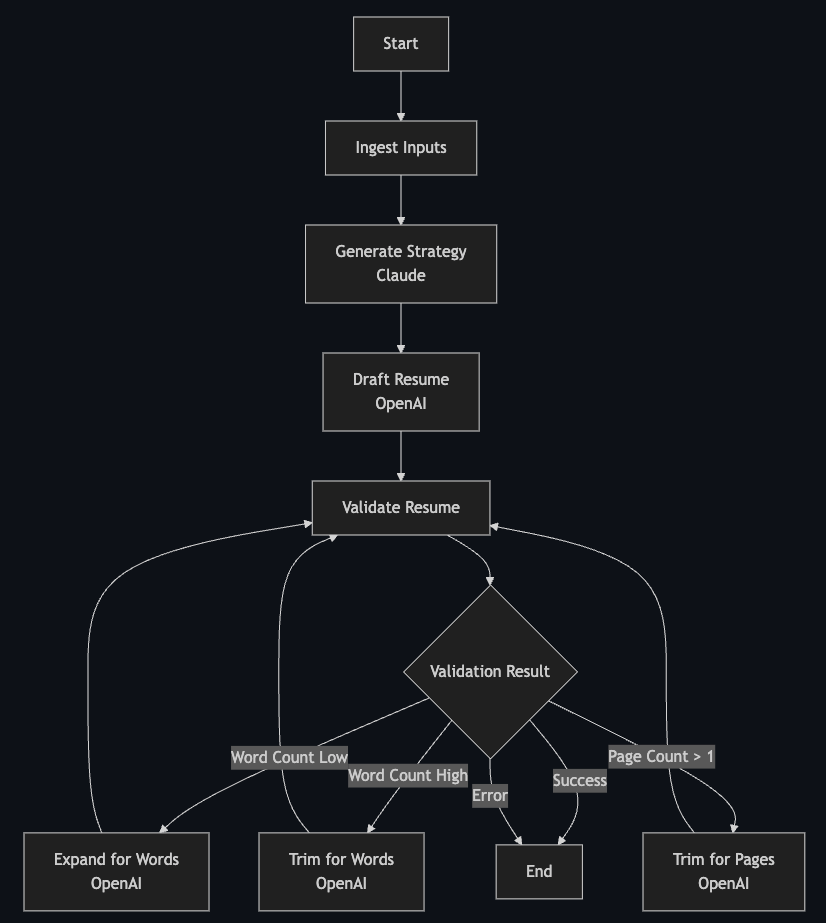
Once the user hits "Tailor Resume," the agent starts moving like a state machine.
First, it ingests the base resume and job description. Nothing fancy here, just parsing inputs.
Then Claude steps in. It analyzes the candidate's experience level, content strength, alignment with the job, and decides what deserves the spotlight. It also decides what gets cut or downplayed. All of this becomes a single JSON "strategy file" that never changes.
Next, OpenAI takes that strategy and builds the resume in structured JSON form. If the strategy says "expand on the user's most recent role" → it expands it. "Downplay the old internship" → it does exactly that. "Emphasize backend skills" → it finds the right bullets and adjusts them.
If the result breaks any rules - too long, too short, doesn't fit on one page - the system loops back and asks OpenAI to refine it. These refinements aren't chaotic; they're surgical. Add 20–40 words here. Remove low-value bullets there. Nothing that destroys high-quality content. The refinements are each LLM instances of their own with different system prompts so we don't blindly make decisions and are strategic with the way we do things.
Why We Take Validation So Seriously
Anyone can generate a resume. But generating one that:
- Fits on exactly one page
- Stays between 360–440 words
- Doesn't hallucinate
- Actually reflects the job description
- And still looks clean in LaTeX
… that's the hard part.
This is why Rezzy validates at two levels:
1. Word Count
A good resume lives between 360–440 words.
Anything less = not enough substance.
Anything more = more than one page.
So the agent adjusts accordingly, and not randomly, it always expands or trims based on strategy.
2. Page Count
After word count is fixed, we compile the resume in LaTeX and literally check the PDF page count.
We don't approximate. We don't estimate. We actually compile it and check.
It's the only reliable way to guarantee one-page output.
Why LangGraph
A normal prompt chain would've fallen apart trying to coordinate all of this.
LangGraph gives us:
- A state machine
- Conditional routing
- Persistence between nodes
- Error handling
- The ability to stream progress to the user
This turns the whole pipeline into a proper "agent system", not a one-shot LLM call that we hope works.
Conclusion
At the end of the day, we believe Rezzy is exactly what users want: A tool they can trust to make good decisions on their behalf.
It all starts with reliable agent architecture that enables us to do exactly that.